Fixing hidden failures in RunNginx and server shutdown
Today was less about adding features, and more about fixing two failure paths that were easy to miss…
The first fix was around go jobs.RunNginx(deployment.ID). Before this, if RunNginx() panicked, the goroutine would just die on its own and the deployment could be left in a confusing state. I added panic recovery inside RunNginx() so the panic can be logged and the deployment status can still be updated to failed.
I made that change because background jobs can fail in places that are easy to forget. From the outside, it can look like nothing happened… but in reality the goroutine already crashed. So the main goal here was not just to prevent a crash, but to make the failure visible and keep the deployment state honest.
The second fix was about shutting down the server properly. Previously I had defer db.Conn.Close() in main(), but http.ListenAndServe(...) blocks forever, which means that defer never actually runs while the server is alive.
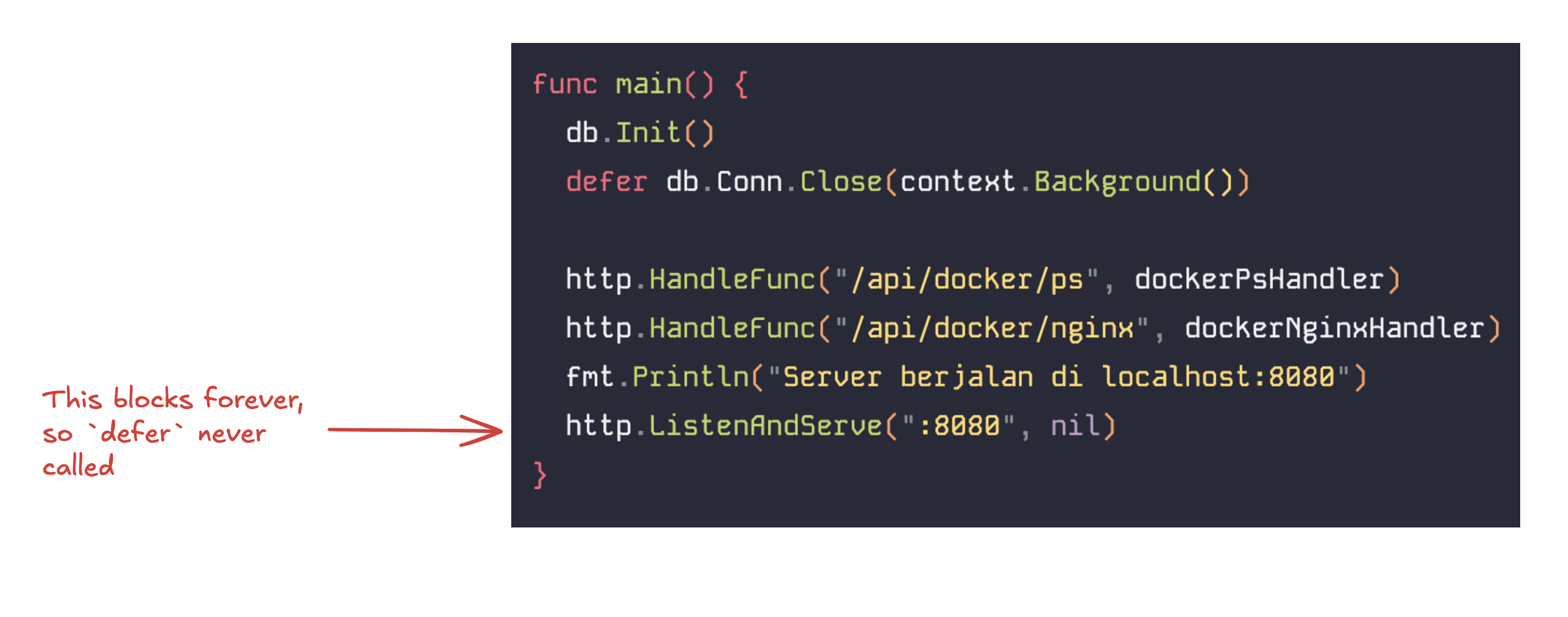
The fix was switching to http.Server with signal handling so the app can shut down more gracefully.
A simple way to notice the problem was to put fmt.Println() inside the defer, run the Go server, then stop it with ctrl + c… the print would never show up. That made it obvious that the cleanup path was not really being reached. After switching to a signal-aware server flow, the shutdown process became much clearer and the database close logic finally has a chance to run.
So both fixes were really about the same thing: handling the parts that happen outside the happy path. One insight I keep getting from this project is that background work and long-running servers can look fine at first, but small lifecycle mistakes like panic handling or misplaced cleanup can make the whole app feel unreliable pretty quickly.